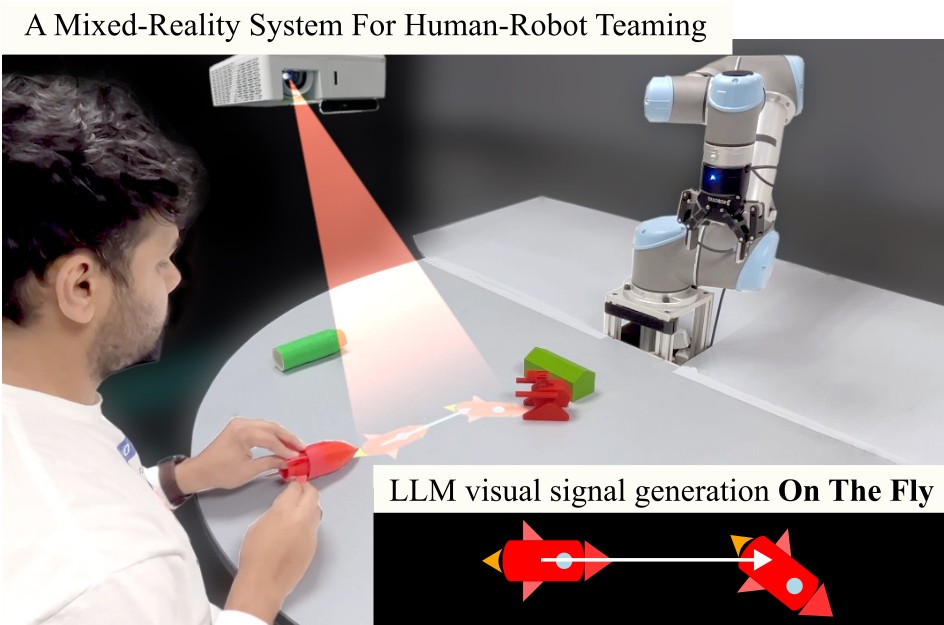
Effective human-robot collaboration hinges on robust communication channels, with visual signaling playing a pivotal role due to its intuitive appeal. Yet, the creation of visually intuitive cues often demands extensive resources and specialized knowledge. The emergence of Large Language Models (LLMs) offers promising avenues for enhancing human-robot interactions and revolutionizing the way we generate context-aware visual cues. To this end, we introduce SiSCo–a novel framework that combines the computational power of LLMs with mixed-reality technologies to streamline the creation of visual cues for human-robot collaboration. Our results show that SiSCo improves the efficiency of communication in human-robot teaming tasks, reducing task completion time by approximately 73% and increasing task success rates by 18% compared to baseline natural language signals. Additionally, SiSCo reduces cognitive load for participants by 46%, as measured by the NASA-TLX subscale, and receives above-average user ratings for on-the-fly signals generated for unseen objects. To encourage further development and broader community engagement, we provide full access to SiSCo’s implementation and related materials on our GitHub repository.